
Web3.com Ventures Original Research Analysis
By 0xFishylosopher
Introduction
“zk-Rollups” has probably been the hottest Web 3 buzzword of the year. With zk-Sync’s v2.0 “baby alpha” mainnet launch in just the past few days, this excitement has reached its zenith [1]. But behind all these buzzwords, what do “zk-Rollups” really refer to? And where does zk-Sync come into play? In this article, I will endeavor to dive deep into the principles and practice of zk-Rollups, explicate the key technical hallmarks of zk-Sync v2.0 as a project, and explore the potential future implications for this long-awaited technology.
Principles of zk-Rollups
Why do we need zk-Rollups in the first place? Sure, Ethereum is great. But in its current state, the network is fundamentally a diseconomy of scale. As network activity increases, gas prices become prohibitively expensive, particularly if there is a surge of network activity all at once. As Ethereum gains popularity in usage and traction over the past few years, its current limited scalability has become the network’s Achilles’ heel.
This is where “rollups” come in — Ethereum rollups are essentially a “plugin” that provides Ethereum with extra magnitudes of scalability and thus fixing its inherent diseconomy of scale. The intuition behind the idea is simple. Imagine you have 5 items that you need to carry from point A to point B. The “regular” way of doing so would be carry Item 1, carry Item 2, etc. one after another. But this is obviously slow and cubersome. A “rollup” is essentially “rolling” all 5 items into a single bag, thus allowing you to make a single trip instead of 5.
But there are two caveats:
- How do we make sure the rollup can “fit” everything?
- How do we make sure the rollup is not spoofed?
zk-Rollups are one of the leading types of rollup techologies (the other being Optimistic Rollups) leveraging “zero-knowledge proofs” to solve these two issues. To address these issues, a zk-Rollup will bundle a certain number of transactions together, do the computation on the L2, and submit both state changes and a “validity proof” to a verifier on the L1 showing that the computations were done with integrity. This “validity proof” takes places in the form of a “Zero-Knowledge Proof,” a mathematical way of telling someone you know something without telling them what you know.

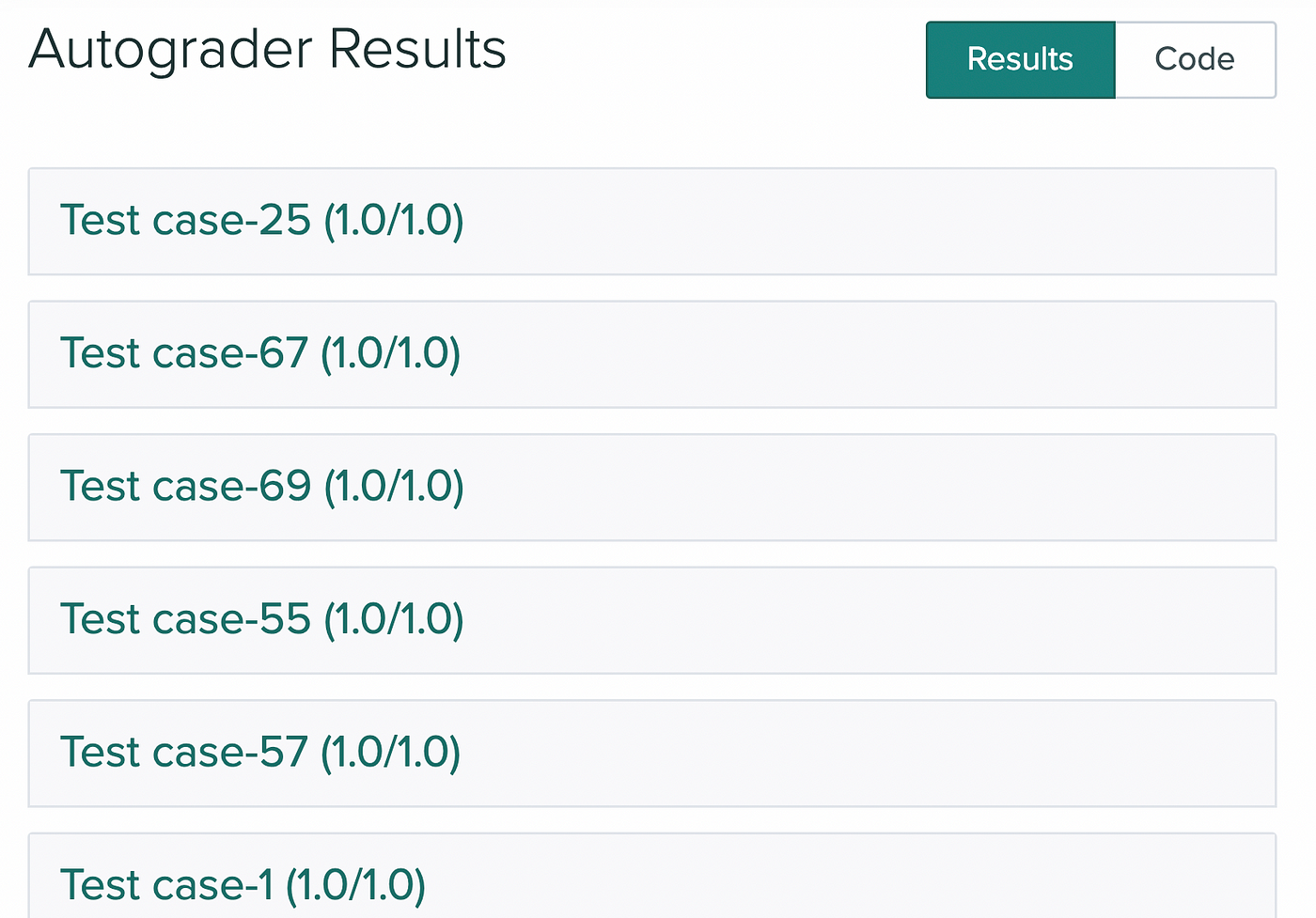
A simple example of a Zero-Knowledge Proof is a code autograder (for CS homework). The autograder is a ”verifier” that gives you a bunch of randomly generated test-cases, and you are a “prover” that must be able to pass all the test-cases to prove that you have the correct code. All the while, you don’t share your code with the autograder directly. And voila, you have just conducted a “Zero-Knowledge Proof,” proving that you know something without saying what you know. [2]
The code autograder above uses an “interactive Zero-Knowledge-Proof,” where the autograder and code-provider directly “interact” with one another. In contrast, most zk-Rollups use a more mathematically complicated non-interactive proof (such as a zk-SNARK, or Zero Knowledge Succinct Noninteractive ARgument of Knowledge), which saves both time and space compared to an interactive proof. While the technical details of zk-SNARKs are beyond the scope of this article, the underlying principle of test-case-passing is the same.
The holy grail of zk-Rollups is a Zero-Knowledge Ethereum Virtual Machine (zk-EVM) that allows developers to port over any Ethereum smart contract without modification onto a zk-Rollup chain. But this is hard. Because every “problem” requires different sets of “test-cases,” developing a “proof algorithm” that can solve every imaginable test-case is a technical bottleneck of Zero-Knowledge Proofs and zk-Rollups.
As Vitalik Buterin himself states:
In general, my own view is that in the short term, optimistic rollups are likely to win out for general-purpose EVM computation and ZK rollups are likely to win out for simple payments, exchange and other application-specific use cases, but in the medium to long term ZK rollups will win out in all use cases as ZK-SNARK technology improves. [3]
Thus, historically zk-Rollups have only been established technologies for application-specific use cases, where “test-cases” are well-defined and limited in scope. However, several projects are rapidly advancing towards the “castle on the hill” — a generic EVM-compatible zk-Rollup algorithm. [4]
zk-Sync v2.0
zk-Sync v2.0 is just one of the many projects in currently in play in developing a zk-EVM (others include StarkNet, Polygon Hermez, and Scroll). Unlike zk-Sync v1.0, which required users to re-build large sections of their codebases to port from the EVM to zk-Sync, in zk-Sync v2.0 programmers can deploy their applications with little-to-no changes — or as zk-Sync may like to claim.
In practice, not all zk-EVMs are created equal. There is a distinct tradeoff between composability (how close it is to original EVM contracts) and performance (how fast the zk-Rollups will run) [6]. Within this tradeoff, zk-Sync chose to completely optimize for performance, thus sacrificing on composibility.
In Vitalik Buterin’s perspective, there are four distinct types of zk-EVMs, summarized in the following chart:

As Vitalik states, in its current state zk-Sync v2.0 is a Type 4 zk-EVM, which is able to compile contracts written in Solidity and high-level languages using its own compiler, which is distinct from the EVM. Because zk-Sync has full control over the design of their compiler, they are able to aggressively optimize for speed and throughput. The cost of this is that some DApps and EVM debugging toolchains may be incompatible with zk-Sync v2.0. Essentially, zk-Sync is the same car shell as Ethereum but with an engine swapped out [5].
Indeed, in its developer documentation Matter Labs claims that while smart contract “read” operations can be integrated without any changes in code, smart contract “write” operations need “additional code” because of “fundamental differences between L1 and L2” [6]. Actually, this is slightly misleading. It is not so much due to a “fundamental difference” between L1 and L2 but more so because of the type of zk-Rollup that Matter Labs has decided to pursue — the Type 4 rollup. Because zk-Sync is fundamentally a Type 4 rollup that uses a different compiler and bytecode, this means that smart contracts have different addresses, and the debugger infrastructure that relies on the analysis of bytecode may not be able to work on zk-Sync v2.0 [7].
In the future, zk-Sync may add in more native support for EVM byte-code, allowing the system to slowly transition to a Type 3 rollup that supports a wider range of these “edge cases.” But for zk-Sync’s Type 4 or Type 3 zk-Rollup to succeed in comparison with Polygon Hermez and Scroll Labs’ Type 2 rollup, which essentially trades speed for wider compatibility, there must be two important preconditions. First, there is only a tiny fraction of unimportant projects that are incompatible with zk-Sync’s custom compiler. Secondly, there is a qualitative difference in zk-Sync’s execution speed compared with a Type 2 zk-EVM.
Unfortunately, I personally believe this is unlikely to be the case. Any advanced development ecosystem relies on a mature “scaffolding” infrastructure, including convenient, modularized, debugging and testing tools. If, as Vitalik postulates, a large portion of EVM-native debugging tools will be unable to port to zk-Sync because of differences in bytecode, then zk-Sync will have to develop its own suite of testing and debugging tools. This is extra overhead that may ultimately hinder the adoption speed of zk-Sync as a L2 solution, compared to its more composable Type 2 zk-EVM competitors such as Polygon Hermez and Scroll.
The Future for zk-Rollups
With many competitive players in the battle for zk-EVMs, arguably it is only a matter of time before we see a fully-functional zk-EVM. But what’s next? A road is only useful so long as there are buildings on the road; the long-term strength of a zk-Rollup comes from the projects using that solution.
Right now, DeFi, GameFi, and mobile applications are the main beneficiaries of zk-Rollup infrastructure. Both DeFi and GameFi are fundamentally economies of scale, as they thrive in an environment where there are lots of people are using them. Mobile applications such as mobile wallets also open the floodgates to the mass consumer that is too lazy (or can’t afford) a Desktop PC. Using zk-Rollups for these situations therefore makes a lot of sense.
But this is by no means the limit of zk-Rollups usefulness. If anything, this is just the beginning. zk-Rollups are to Ethereum what 5G is to the Internet. Just as 5G can enable a new world of IoT applications and systems, zk-Rollups may also open the floodgates to a “Blockchain of Things,” allowing the digital appliances of our physical world — fridges, watches, traffic lights and all — to be intergrated with smart contracts secured on Ethereum.
One of the largest arguments against the IoT is that it will allow Big Tech to overstep into our everyday life. But with a “Blockchain of Things,” we can enjoy the conveniences of IoT without worrying about our smart-appliances being compromised on a centralized database. Instead of convenience OR privacy, we can have convenience AND privacy. That’s the world that zk-Rollups can promise us.
🐦 @0xfishylosopher
📅 31 October 2022
This information is purely educational and should not be taken as financial advice. All views expressed are those of the author’s and are not necessarily endorsed by Web3.com Ventures.
References
[1] https://blog.matter-labs.io/baby-alpha-has-arrived-5b10798bc623
[2] Adapted from https://pages.cs.wisc.edu/~mkowalcz/628.pdf
[3] https://vitalik.ca/general/2021/01/05/rollup.html
[4] https://www.coindesk.com/tech/2022/07/20/the-sudden-rise-of-evm-compatible-zk-rollups/
[5] https://cryptobriefing.com/the-race-scale-ethereum-zkevm-rollups/
[6] https://docs.zksync.io/dev/contracts/#porting-smart-contracts













